大数据开源系统,构建高效数据处理的利器
时间:2025-01-14 来源:网络 人气:
你有没有想过,在这个信息爆炸的时代,我们每天产生的数据量简直就像海浪一样,一波接一波地涌来?别担心,今天我要给你揭秘的就是那些像超级英雄一样,能够处理海量数据的开源系统!?♂♀?
大数据的海洋,开源系统的航标
想象你站在海边,看着那无边无际的海洋,你会怎么做?是选择独自面对,还是寻找一艘船,让它带你驶向未知的海域?在处理大数据的世界里,开源系统就像是那艘船,它们能够带你穿越数据的海洋,探索其中的奥秘。
Apache Storm:实时数据的守护者
首先,让我们来看看Apache Storm。这个由Twitter公司开源的实时分布式流处理系统,简直就是实时数据的守护者。它广泛应用于实时分析、在线机器学习、分布式RPC、ETL等场景。
数据封装的艺术
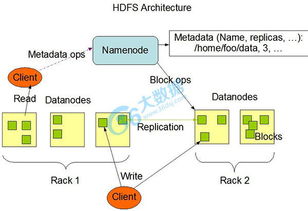
在Storm的世界里,数据被封装成一个个叫做tuple的小精灵。每个tuple就像是一份快递,它承载着数据流中的信息,穿梭在分布式系统中。一条数据流就是一个无边界的tuple序列,而这些tuple序列可以以分布式的方式创建和处理。
速度与激情
Storm支持水平扩展,这意味着你可以像堆积木一样,不断增加处理数据的节点,让处理速度越来越快。而且,它的高容错性保证数据能被处理,不会因为某个节点的故障而丢失。
Spark Streaming:大数据的快车道
接下来,我们要介绍的是Spark Streaming。这个由Apache Spark团队开发的实时数据流处理系统,简直就是大数据的快车道。它能够处理来自各种数据源的数据流,包括Kafka、Flume、Twitter等。?♂♀?
数据处理的艺术
Spark Streaming将数据流处理与Spark的强大数据处理能力相结合,使得你可以轻松地对实时数据进行复杂的处理和分析。无论是简单的过滤、聚合,还是复杂的机器学习算法,Spark Streaming都能轻松应对。
弹性伸缩
Spark Streaming同样支持水平扩展,这意味着你可以根据数据量的变化,动态地调整处理能力。而且,它的容错性也非常出色,能够保证数据的完整性和准确性。
Apache Flink:大数据的瑞士军刀
我们要介绍的是Apache Flink。这个由Apache Software Foundation维护的开源流处理框架,简直就是大数据的瑞士军刀。它支持流处理和批处理,能够处理来自各种数据源的数据流,包括Kafka、HDFS、Twitter等。?
流批一体的艺术
Flink的流批一体特性,使得你可以同时处理实时数据和批量数据,无需进行数据转换。这使得Flink在处理复杂的数据分析任务时,具有极高的灵活性和效率。
强大的容错性
Flink的容错性也非常出色,它采用了分布式快照技术,能够保证数据的完整性和准确性。而且,它的性能也非常优秀,能够处理大规模的数据流。
:开源系统的力量
通过以上介绍,我们可以看到,开源系统在处理大数据方面具有巨大的潜力。无论是Apache Storm、Spark Streaming,还是Apache Flink,它们都能够帮助我们轻松地处理海量数据,探索数据的奥秘。
在这个信息爆炸的时代,开源系统就像是我们的超级英雄,它们能够帮助我们应对各种挑战,探索未知的世界。所以,让我们一起拥抱开源系统,开启大数据的探索之旅吧!
相关推荐


教程资讯
教程资讯排行